
本周数据
概要
| 投入 | -20170 |
|---|---|
| 收益率 | 本周: 3.61% / 沪深300:1.19% 本年: 3.92% / 沪深300:0.33% |
| 账本 | 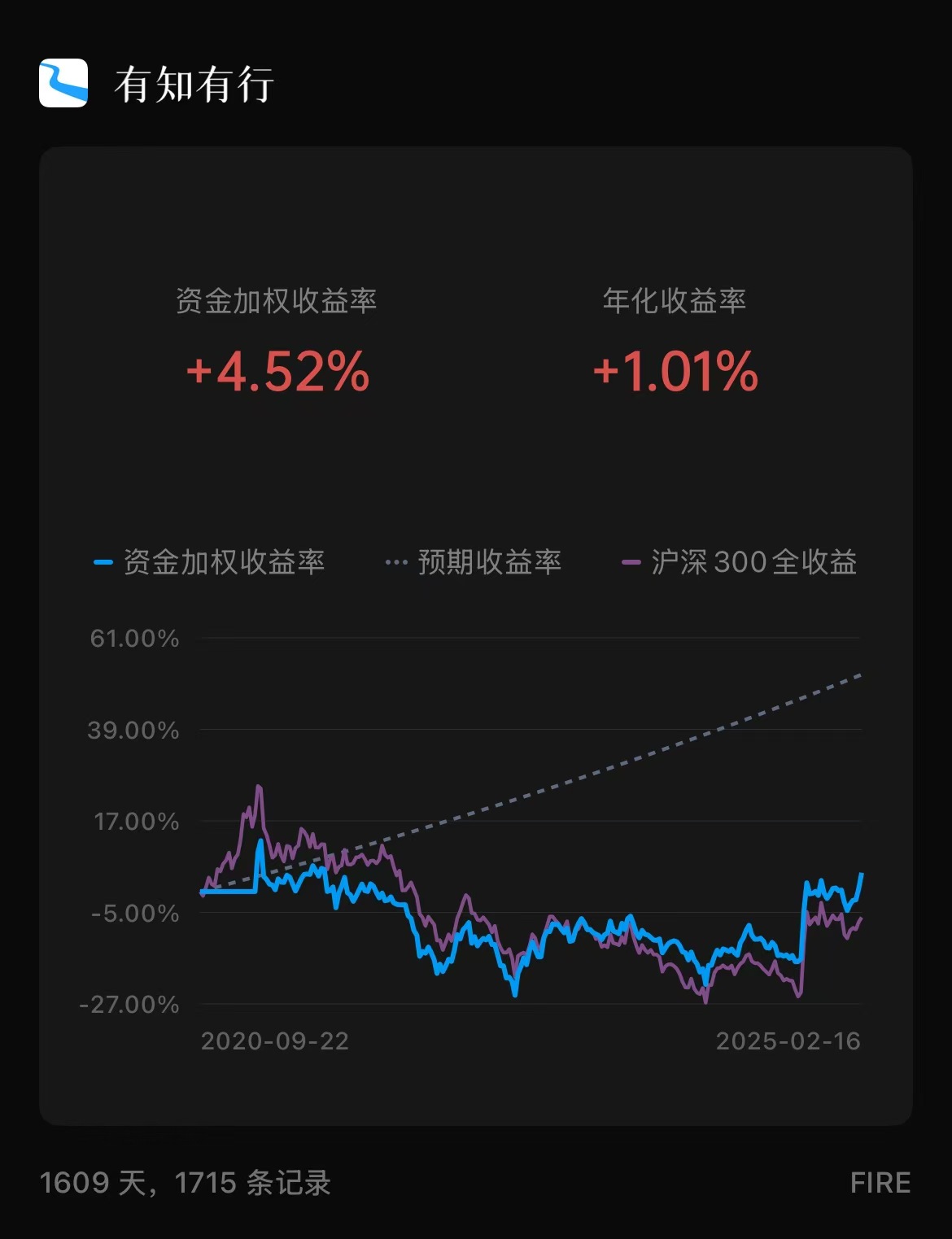 |
| 消费 | 979 |
交易
- 支付宝基金账户转出 20170,减些仓位到余额宝
感想
DeepSeek 降本的关键点
MoE (mixture of experts)混合专家模型,显著降低训练和推理的计算成本
1
2
3
4
5
6
7
8模型预设一组专家,在训练或推理时,只需要激活一部分参数,会自动学习针对不同任务路由到哪个专家.
DeepSeek 的模型拥有超过 6000 亿个参数,相⽐之下,Llama 405B 有 4050 亿参数,
Llama 70B 有 700 亿参数。从参数规模上看,DeepSeek 模型拥有更⼤的信息压缩空间,可以
容纳更多来⾃互联⽹的世界知识。但与此同时,模型每次只激活约 370 亿个参数。也就是说,在
训练或推理过程中,只需要计算 370 亿个参数。相⽐之下,Llama 模型每次推理都需要激活
700 亿或 4050 亿个参数。因此,采⽤混合专家架构可以显著降低训练和推理的计算成本。MLA(Multi-Modal Learning Architecture)多模态学习架构,大幅度降低内存压力
1 | ⽤于减少推理过程中的内存占⽤,在 CUDA 层甚至更底层做编码。 |